Parallel processing, the method of
having many small tasks solve one large problem, has emerged as a key enabling
technology in modern computing. The past several years have witnessed an
ever-increasing acceptance and adoption of parallel processing, both for
high-performance scientific computing and for more “general-purpose"
applications, was a result of the demand for higher performance, lower cost,
and sustained productivity. The acceptance has been facilitated by two major
developments: massively parallel processors (MPPs) and the widespread use of
distributed computing.
MPPs are now the most powerful computers
in the world. These machines combine a few hundred to a few thousand CPUs in a
single large cabinet connected to hundreds of gigabytes of memory. MPPs offer
enormous computational power and are used to solve computational Grand
Challenge problems such as global climate modeling and drug design. As
simulations become more realistic, the computational power required to produce
them grows rapidly. Thus, researchers on the cutting edge turn to MPPs and
parallel processing in order to get the most computational power possible.
The
second major development affecting scientific problem solving is distributed
computing. Distributed computing is a process whereby a set of computers
connected by a network are used collectively to solve a single large problem.
As more and more organizations have high-speed local area networks
interconnecting many general-purpose workstations, the combined computational
resources may exceed the power of a single high-performance computer. In some
cases, several MPPs have been combined using distributed computing to produce
unequaled computational power. The most important factor in distributed
computing is cost. Large MPPs typically cost more than $10 million. In
contrast, users see very little cost in running their problems on a local set
of existing computers. It is uncommon for distributed-computing users to
realize the raw computational power of a large MPP, but they are able to solve
problems several times larger than they could use one of their local computers.
Common
between distributed computing and MPP is the notion of message passing. In all
parallel processing, data must be exchanged between cooperating tasks. Several
paradigms have been tried including shared memory, parallelizing compilers, and
message passing. The message-passing model has become the paradigm of choice,
from the perspective of the number and variety of multiprocessors that support
it, as well as in terms of applications, languages, and software systems that
use it.
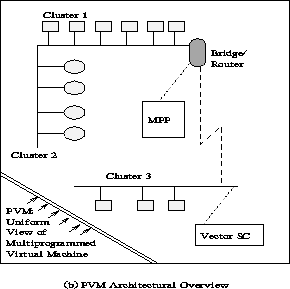
The
Parallel Virtual Machine (PVM) system described in this book uses the message passing
model to allow programmers to exploit distributed computing across a wide variety
of computer types, including MPPs. A key concept in PVM is that it makes a collection
of computers appear as one large virtual machine, hence its name.
0 comments: